
从本地导入数据
- 利用Matlab读取文件命令
importdata()命令提供了读取多种数据格式文件的接口,详细的命令使用方法和案例可以在Matlab窗口中输入‘doc importdata’来查看,类似的命令还有xlsxread(),load()等。
help importdata
importdata - 从文件加载数据
此 MATLAB 函数 将数据加载到数组 A 中。
A = importdata(filename)
A = importdata('-pastespecial')
A = importdata(___,delimiterIn)
A = importdata(___,delimiterIn,headerlinesIn)
[A,delimiterOut,headerlinesOut] = importdata(___)
-
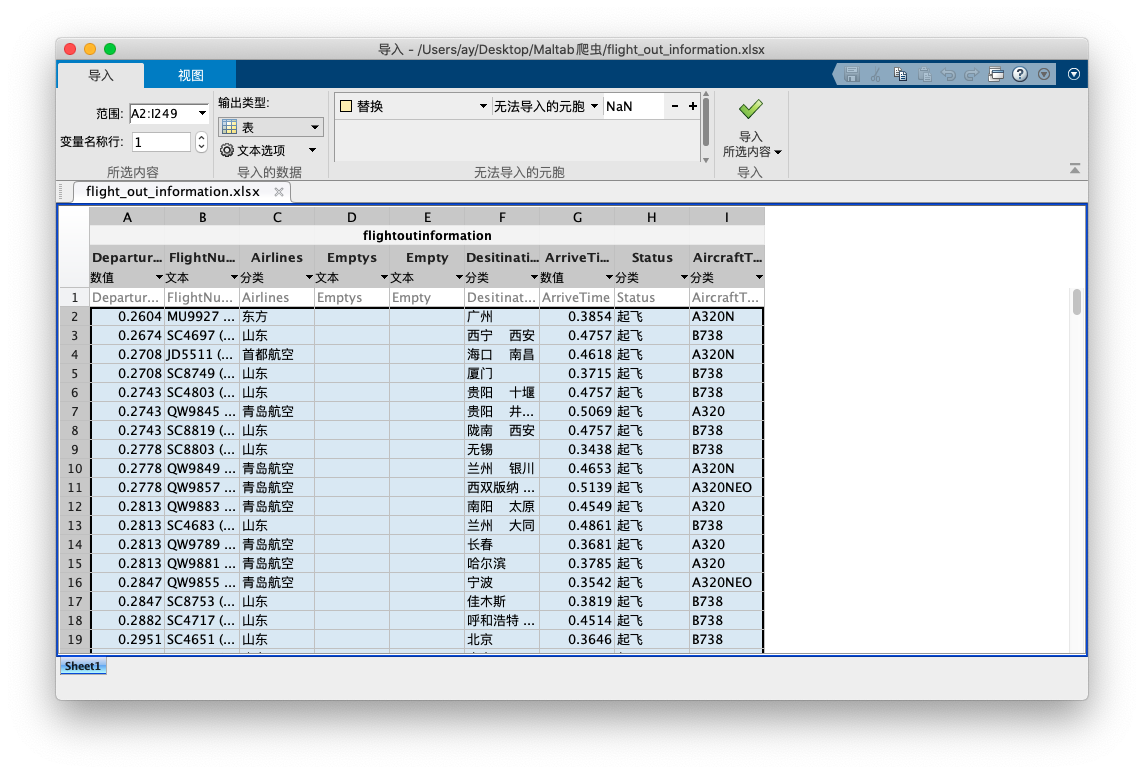
利用Matlab导入数据窗口
Matlab也提供了导入数据的UI窗口,在命令窗口中输入‘uiimport’,之后选择要导入的数据文件或者从剪切板导入,即可打开导入数据窗口,可以选择导入数据的数据范围,以及输出的数据类型与变量名等。
从互联网获取数据
在当今大数据与互联网紧密结合的时代,尤其是人工智能方法的兴起,数据已经成为许多行业制胜的关键。想要从互联网上获取数据,学会应用爬虫技术是我们必须具备的能力。
2019年全国大学生数学建模竞赛C题,机场的出租车问题,就明确要求收集国内某一机场及其所在城市出租车的相关数据,我们很容易在机场网站上找到公布的航班信息,但是怎么将信息下载并处理成我们想要的格式,便于我们对数据进行分析时我们所关注的重点。大量数据的情况下,复制粘贴显然是不可取的,一方面是工作量的巨大,另一方面复制往往不能得到我们想要的数据格式。而爬虫技术能够利用计算机自动化处理信息的特点,将数据完整且规范的爬取到,大大降低了竞赛当中找数据的时间和精力。
本章将以获取青岛流亭机场某一天的航班信息为例,来展开介绍爬虫的基本流程和简单原理。
HTTP基本原理
在用Matlab进行爬虫实践之前,我们必须了解一些网页运行的基础知识,如HTTP原理,网页的基本知识,爬虫的基本原理等等。
URL和超文本
- URL
即我们熟悉的网址,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志,就是指网络地址。
- 超文本,其英文名称叫做hypertext,我们在浏览器看到的网页就是超文本解析而成,其网页源代码就是一系列HTML代码,里面包含了一系列标签。而浏览器解析这些标签,就能够形成简易的我们平常看到的网页,网页的源代码HTML就可以叫做超文本。
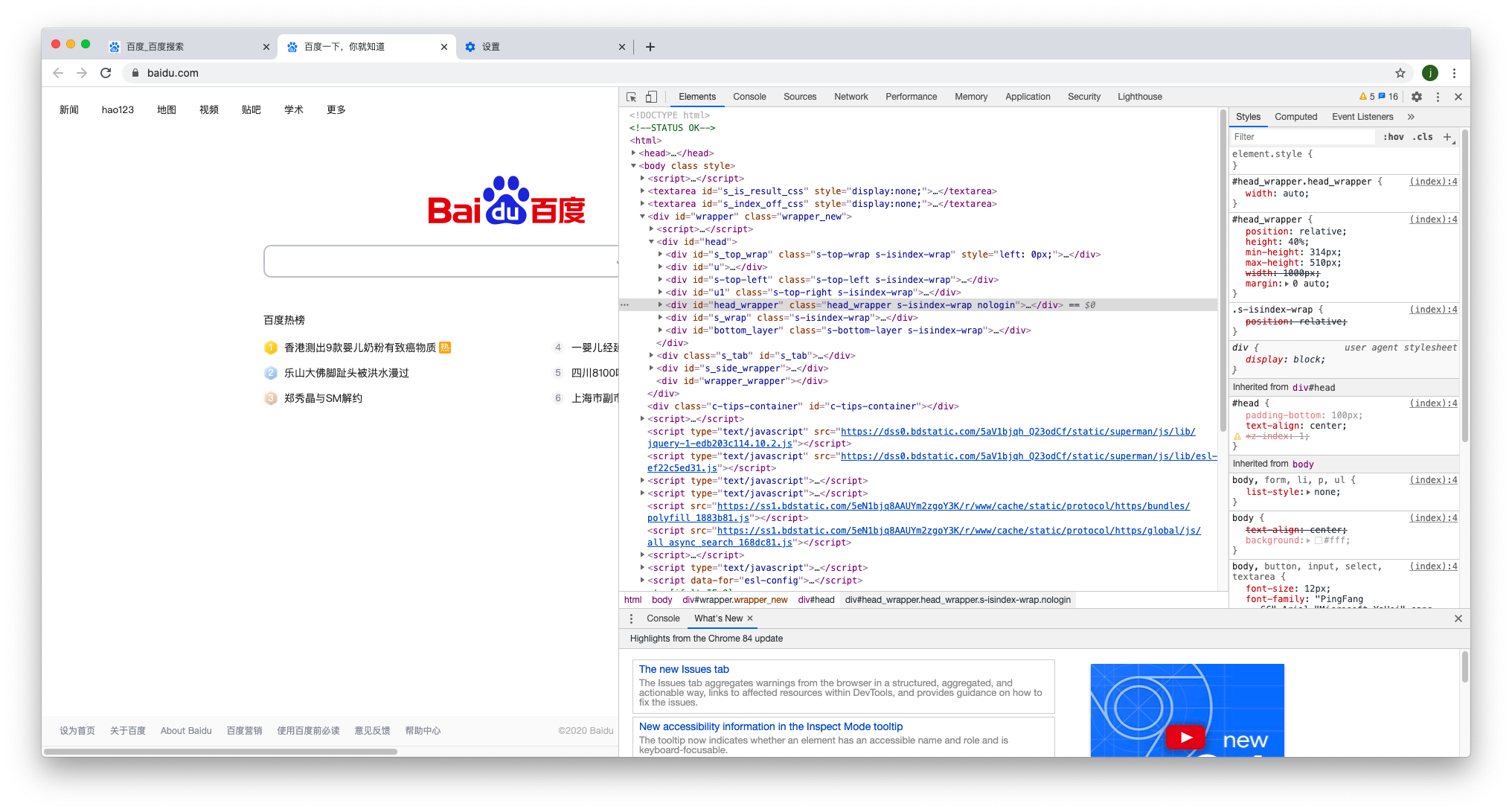
例如,我们打开百度首页,右键检查,在弹出的窗口Elements选项卡下就可以看到这个网页的源代码,这些源代码都是超文本。
HTTP和HTTPS
http和https都是访问网络资源的协议类型,除了这两种我们还会看到比如ftp,sftp,smb的协议类型。在爬虫中,通常爬取的页面就是http或https协议的。
HTTP的全称Hyper Text Transfer Protocol,中文名叫做超文本传输协议,它能保证高效而准确地传送超文本文档。
HTTPS的全称Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的HTTP通道,简单讲就是HTTP的安全版本。
HTTP请求过程
我们在浏览器输入了一个URL,回车之后便会在浏览器中观察到页面内容。实际上,这个过程浏览器想网站所在的服务器发送了一个请求,网站服务器接收到这个请求之后进行处理和解析,然后返回对应的响应,由本地浏览器解析,呈现出网页。
网页基础
网页的组成
网页可以分为三大部分——HTML、CSS、JavaScript。HTML构成了网页的基本框架,而CSS对网页进行了修饰,使其更加美观。JavaScript定义了网络的交互和动画功能。这三个基本部件相互配合构成了整个浏览器的网页。
- HTML
HTML是一种描述网页的语言,其全称为Hyper Text Markup Language,即超文本标记语言。网页包括文字、按钮、图片视频等元素,不同类型的元素通过不同的标签来表示。这些标签定义的节点元素相互嵌套和组合形成了复杂的层次关系,构成了网页的基础架构。
- CSS
CSS全称叫作Cascading Style Sheets,即层叠样式表。层叠是指当在HTML中引用了数个样式文件,并且样式发生冲突时,浏览器能依据顺序处理。样式是指在网页中的文字大小、颜色、元素间距排列等格式。
- JavaScript
JavaScript,简称JS,是一种脚本语言。HTML与CSS配合使用,提供给用户的只是一种静态信息,无法进行交互。而我们在网页中需要一些交互,比如点击下载,跳转页面,以及提示框等这些都是有JS来完成的。
爬虫的基本原理
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。
- 获取网页
爬虫首先要做的工作就是获取网页,即获取网页的源代码。源代码里面包含了网页的部分有用信息,所以只要报源代码获取下来,就能从中提取想要的信息。再确定想要爬取的网页网址之后可以利用Matlab的webread()函数来完成获取网页的功能。
语法
data = webread(url)
描述
数据= webread (url)从 指定的 Web 服务中读取内容,并在data中返回内容。
Web 服务提供RESTful,它返回以 Internet 媒体类型(如 JSON、XML、图像或文本)格式格式化的数据。
- 提取信息
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。在windows系统中,可以借助Matlab与IE交互的方式,创建COM服务器,然后根据网页标签或者属性定位信息,从而将信息爬取到本地。也可以利用最通用的方法,采用正则表达式匹配文本中我们需要的信息格式,这是一个通用且有效的方法。
提取信息时爬虫非常重要的部分,它可以从杂乱无章的文本信息中整理得到我们想要的信息以及信息格式,为我们后续处理和分析数据奠定良好的基础。
- 保存数据
提取信息后我们可以将信息保存下来,以备后续使用。保存的方法和保存的格式也是多种多样,Matlab中有很多操作文件的函数,比如xlswrite或者writetable等。
爬取航班信息实例
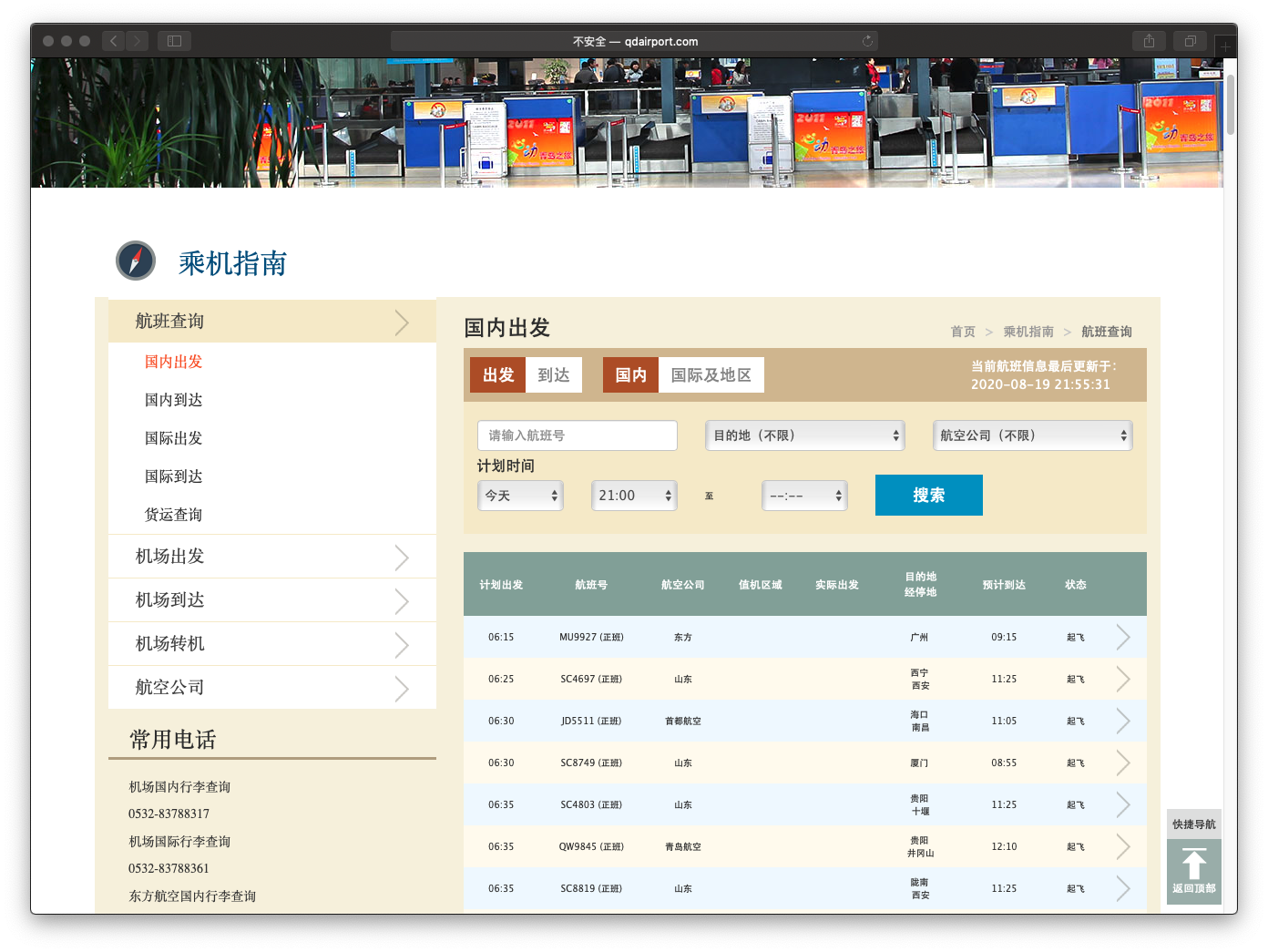
以抓取青岛流亭机场当日航班信息为例,从浏览器上查到青岛流亭机场官方网站,网页中公布了当日的所有航班信息,我们将网址记录下来。
Matlab爬虫方法一:与IE交互(注意:只能在Windows使用)
由于网页的结构有一定的规律,在HTML超文本语言中会有标签属性等定义某一个网页元素,在浏览器中右击想要爬取的信息,点击检查,即可查询到该元素所属的标签或者Class,根据这个信息可以获取到想要的元素。
利用matlab中的actxserver函数,创建com服务器,将网页中的信息在Matlab中获取到:
>> help actxserver
actxserver - 创建 COM 服务器
此 MATLAB 函数 创建一个本地 OLE 自动化服务器,其中 progid 是与 OLE 兼容的 COM 服务器的编程标识符
(ProgID)。此函数返回服务器的默认接口的句柄。
c = actxserver(progid)
c = actxserver(progid,'machine',machineName)
创建好服务器之后,在弹出的IE窗口中右击网页元素,查看标签名,根据标签名字获取信息。
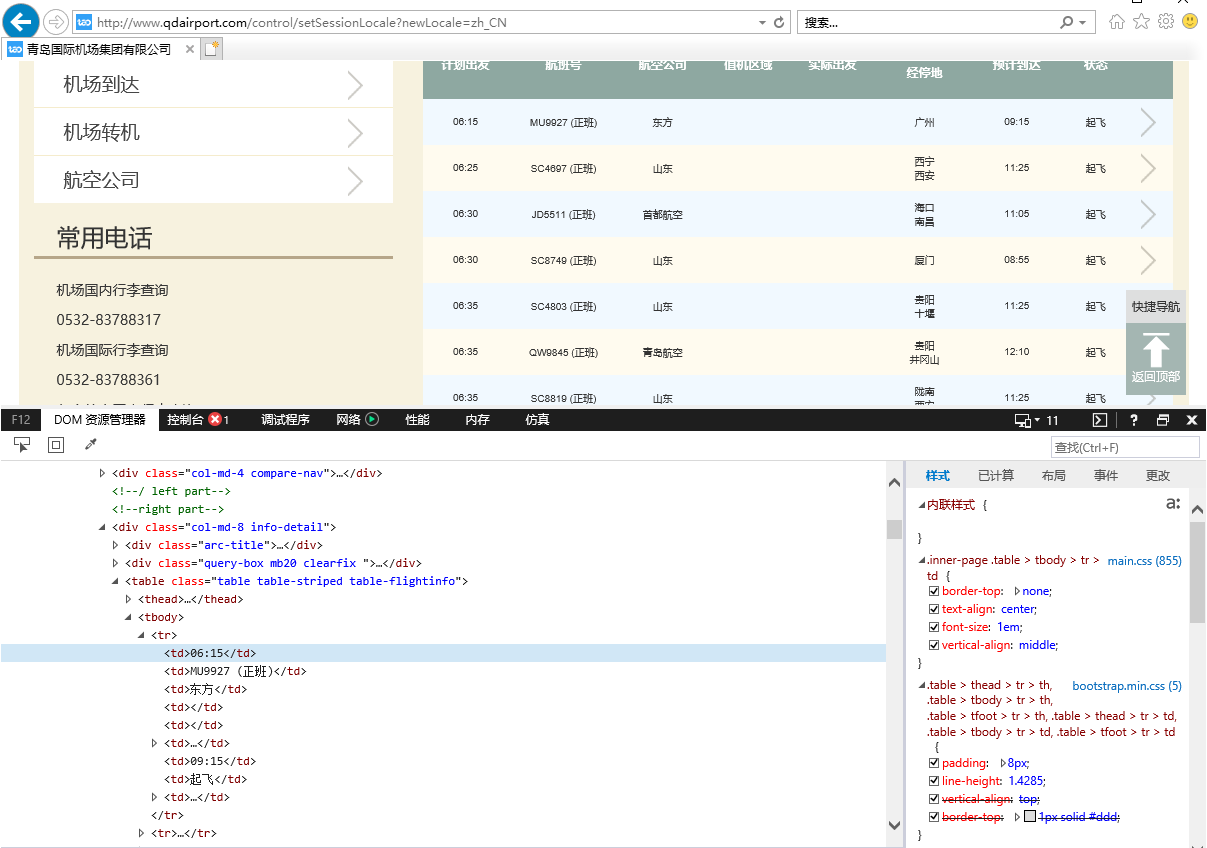
可以看到列表的标签为tbody,而每一行的标签为tr,每一个元素的标签为td,可以按照标签名为td将网页中的元素都获取到。具体代码为:
clc
clear
%% 创建服务器
ie=actxserver('internetexplorer.application');%注意只能在Windows运行
ie.Navigate('http://www.qdairport.com/control/FindHbcx?catalogId=head_hbxx0101'); %获取网页
ie.visible = 1;
while ~strcmp(ie.readystate,'READYSTATE_COMPLETE')
pause(0.01)
end
%% 获取网页中航班信息
NumFlight = ie.document.body.getElementsByTagName('td').length; %获取所有td标签的个数
flight_info = cell(floor(NumFlight/9),9); %创建空的元胞数组用来存数据
row_info = ie.document.body.getElementsByTagName('td'); %获取所有td标签的内容
h = waitbar(0); % 进度条
t=1;
for k = 0:9:floor(NumFlight-2) %循环每一行
n = 0;
for i = k:k+8 %循环每一个元素
n= n+1;
flight_info(t,n) = cellstr(row_info.item(i).innerText); %获取信息并存储
end
t = t+1;
str = ['Downloading the information:',num2str(k/NumFlight*100),'%'];
waitbar(k/NumFlight,h,str); % 进度条
end
Quit(ie);
delete(ie);
close(h);
查看第一页的信息之后发现,该网页并没有公布航班机型的信息,而是在点击每一行最后的箭头,跳转到另一个网页,才有航班信息。仔细分析另一个网页的网址规律,可以发现,只要将网址中间的航班号进行替换就可以查询到该航班的飞机型号。
有了这一发现,就可以生成每个航班对应可以查机型的网址。然后当然可以利用方法一,创建COM服务器,获取该信息标签或Class,从而抓取该信息,但是这样循环创建多个服务器,会导致程序较慢,资源开销比较大。
Matlab爬虫第二种方法:
在这里,我们介绍第二种方法,借助正则表达式,用webread函数轻松获取信息。经过细致浏览可以发现,所有机型信息都处于class="text"这一类内,而且机型都是由大写字母与数字或者大写字母数字横线数字的组合,比如A320,B787-8。用正则表达式匹配为'(class="text">\w+<)|(class="text">\w+-\d)'。关键代码为:
typemeta = webread(ref);
flight_t = regexp(typemeta,'(class="text">\w+<)|(class="text">\w+-\d)','match');
这种方法是最传统但是最有效的方法,注意在正则匹配的时候一定要保证定位准确且唯一,不要匹配到类似但是不相关信息。最后将爬取到的数据保存到Excel即可。
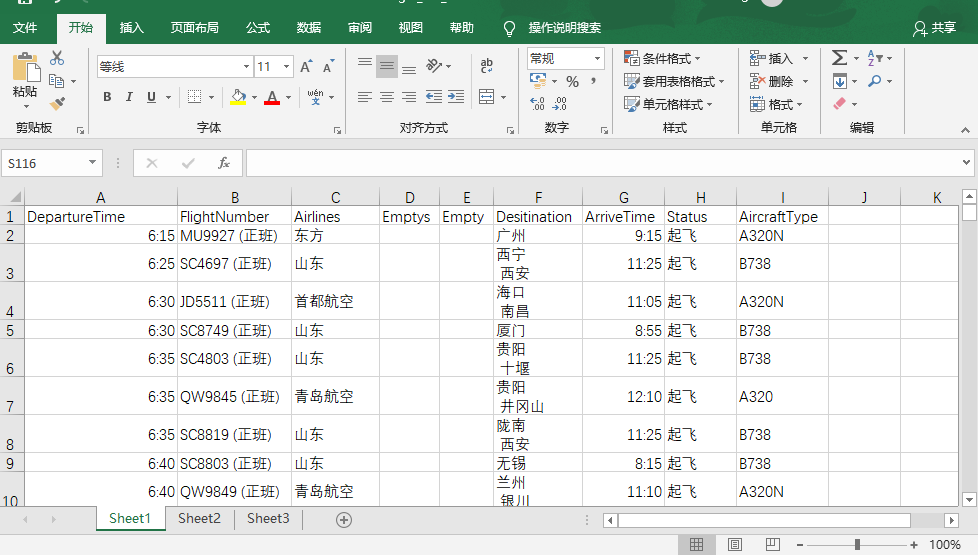
抓取流亭机场当日航班信息完整代码
clc
clear
%% 创建服务器
ie=actxserver('internetexplorer.application');%注意只能在Windows运行
ie.Navigate('http://www.qdairport.com/control/FindHbcx?catalogId=head_hbxx0101'); %获取网页
ie.visible = 1;
while ~strcmp(ie.readystate,'READYSTATE_COMPLETE')
pause(0.01)
end
%% 获取网页中航班信息
NumFlight = ie.document.body.getElementsByTagName('td').length; %获取所有td标签的个数
flight_info = cell(floor(NumFlight/9),9); %创建空的元胞数组用来存数据
row_info = ie.document.body.getElementsByTagName('td'); %获取所有td标签的内容
h = waitbar(0); % 进度条
t=1;
for k = 0:9:floor(NumFlight-2) %循环每一行
n = 0;
for i = k:k+8 %循环每一个元素
n= n+1;
flight_info(t,n) = cellstr(row_info.item(i).innerText); %获取信息并存储
end
t = t+1;
str = ['Downloading the information:',num2str(k/NumFlight*100),'%'];
waitbar(k/NumFlight,h,str); % 进度条
end
Quit(ie);
delete(ie);
close(h);
%% jump to another page for flight type com服务器方法
% urls = 'http://www.qdairport.com/control/FindHbcxDetail?catalogId=head_hbxx0101&&HBH=HHHHH%20&&serviceName=domesticDeparture';
% h = waitbar(0,'Downloading the AircraftType: ');
% for i = 1:length(flight_info)
% HBH = char(flight_info(i,2));
% HB = strsplit(HBH,' ');
% ref = char(strrep(urls,'HHHHH',HB(1)));
% ies=actxserver('internetexplorer.application');
% ies.Navigate(ref);
% while ~strcmp(ies.readystate,'READYSTATE_COMPLETE')
% pause(0.01)
% end
% flight_t = ies.document.body.getElementsByClassName('text');
% flight_type = flight_t.item.innerText;
% flight_info(i,end) =cellstr(flight_type);
% str = ['Downloading the AircraftType:',num2str(i/length(flight_info)*100),'%'];
% waitbar(i/length(flight_info),h,str);
% Quit(ies);
% delete(ies);
% end
% close(h)
%% jump to another page for flight type webread正则匹配方法
urls = 'http://www.qdairport.com/control/FindHbcxDetail?catalogId=head_hbxx0101&&HBH=HHHHH%20&&serviceName=domesticDeparture';
h = waitbar(0,'Downloading the AircraftType: ');
for i = 1:length(flight_info)
HBH = char(flight_info(i,2));
HB = strsplit(HBH,' ');
ref = char(strrep(urls,'HHHHH',HB(1)));
typemeta = webread(ref);
flight_t = regexp(typemeta,'(class="text">\w+<)|(class="text">\w+-\d)','match');
flight_type = strsplit(char(flight_t),{'>','<'});
flight_info(i,end) =cellstr(flight_type{1,2});
str = ['Downloading the AircraftType:',num2str(i/length(flight_info)*100),'%'];
waitbar(i/length(flight_info),h,str);
end
close(h)
%% to xlsx
data = cell2table(flight_info,'VariableNames',{'DepartureTime','FlightNumber','Airlines','Emptys','Empty','Desitination','ArriveTime','Status','AircraftType'});
filename = 'flight_out_information.xlsx';
writetable(data,filename);
fprintf('All Done')