

作为一名数据科学家,训练您的机器学习模型只是为客户提供解决方案的一部分。 除了生成和清理数据、选择和调整算法之外,您还需要交付和部署结果,以便在生产中使用。 这本身就是一个庞大的领域,具有不断发展的工具和标准。 在这篇文章中,我的目标是提供一份实用指南,说明如何使用当前可用的最先进的工具和最佳实践来做到这一点。 无论实际的机器学习问题本身如何,我们都将构建一个可以作为您部署任务的起点的系统! 我的目标不是介绍使用过的工具表面的最小应用程序,而是介绍最佳实践并演示高级功能,这样您就不必费力地学习。 从自己的错误中学习固然很好,但提前思考而不犯这些错误要好更多。
今天我们选择的部署架构是FastAPI和Docker, 他们的优点这里就不列举了,Fast API是现在最前沿的Python-web框架,而Docker是容器化部署的最佳选择,保证更快速的应用部署和交付。
[[1.概述]]
1 设计你的机器学习应用
今天我们从一个案例入手,利用Fast API和Docker构建一个人工智能应用,争取代码框架的普适性,适用于多种人工智能应用的部署。
主要部署步骤:
- 打包你的模型并构建一个 API 来与之通信,
- 设计一个方便简单的用户界面,
- 搭建合适的开发环境
virtualenv, - 使用 FastAPI,
- 通过包装您的机器学习模型为未来的代码更改做准备,
- 使用依赖注入使测试更容易,
- 验证用户输入,
- 使用 mock 正确测试 API,
- 用 Docker 和 Docker compose 打包,
- 最后是如何使用 GitHub Actions 进行自动化测试。

我们的应用程序将通过一个 API 进行通信,该 API 将被打包在一个 Docker 容器中。 在这个简单的案例中,在应用程序本身中,我们需要做三件事:处理输入、进行预测、处理输出并将其返回给用户。 使用 FastAPI,输入将是 JSON,如下所示:
{
“data”:[[0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296,15.3,396.9,4.98]]
}
这将由 FastAPI 在内部转换为适当的 Python 对象。 (稍后会详细介绍,因为这是 FastAPI 中最简洁的功能之一。)我们需要为 scikit-learn 模型处理这个,这意味着将其转换为 NumPy 数组。 它可用于计算我们的预测,我们将再次将其转换为 FastAPI 使用的格式。 最后,用户会收到一个类似于输入的 JSON:
{
“data”:[29.813999999999993]
}
2. 开发环境
这里推荐使用miniconda管理python虚拟环境。创建虚拟环境之后,激活,安装FastAPI基本环境。
conda create -n fastapi
conda activate fastapi
conda install fastapi
conda install uvnicorn
3. 搞起来
3.1 数据和模型–波士顿房价预测案例
这篇博客就不详细展开数据分析和模型构建部分了,详细的代码可到我的github仓库进行查看。
[模型构建Jupyter notebook](RF_Boston · flionay/FastapiAndDocker_MLApp - 码云 - 开源中国 (gitee.com))
3.2 构建FastApi服务
主要是有两个核心文件,模型训练好之后保存,然后创建一个机器学习模块,利用import倒入,在fastapi主应用中创建单例模式。
# ML_Module/model.py
import joblib
class ModelApp():
def __init__(self):
# load the model
print("------loading model------")
self.model = joblib.load('./RF_Boston/MLP.weight')
# load the scaler
print("------loading scaler-----")
self.x_scaler = joblib.load('./RF_Boston/x_scaler')
self.y_scaler = joblib.load('./RF_Boston/y_scaler')
def input_process_component(self, input_data):
'''
:param data:
:return:
模型预测前 数据处理 组件
'''
# feature selection
input_data = input_data[[True, False, False, False, True, True, False, True, False,
False, False, False, True]]
input_data = self.x_scaler.transform(input_data.reshape((1, -1)))
return input_data
def output_process_component(self, ypre):
'''
模型预测后,反归一化组件
:return:
'''
out = self.y_scaler.inverse_transform(ypre.reshape((1, -1)))
return out
# main.py
from fastapi import FastAPI
from pydantic import BaseModel,ValidationError,validator
from ML_Module.model import ModelApp
from typing import List
import numpy as np
import warnings
warnings.filterwarnings("ignore")
app = FastAPI(
description="FastAPI for MachineLearning Application",
version="0.1"
)
# 实例化 应该就加载了
model_app = ModelApp()
# api
@app.get('/')
async def index():
return {"info": "Boston House Pricing"}
class PredictRequest(BaseModel):
data: List[List[float]]
@validator("data")
def check_dimensionality(cls, v):
n_features = 13
for point in v:
if len(point) != n_features:
raise ValueError(f"Each data point must contain {n_features} features")
return v
class PredictResponse(BaseModel):
data: List[float]
@app.post("/predict", response_model=PredictResponse)
def predict(input_data: PredictRequest):
# input data process
input_data = np.array(input_data.data[0])
input_data = model_app.input_process_component(input_data)
# model prediction
out = model_app.model.predict(input_data)
# output data process
out = model_app.output_process_component(out)
return PredictResponse(data=[out])
这样就能保证模型一直处于加载状态,而且是单例模式。
单例模式指确保某个类在整个系统中只存在一个实例的一种设计模式 使用单例模式的好处:
1、每个实例都会占用一定的内存资源,且初始化实例时会影响运行性能,所以当整个系统只需一个实例时,使用单例模式不仅可减少资源占用,而且因为只初始化一次,还可以加快运行性能。例如当程序通过一个类来读取配置信息,而程序多个地方需要使用配置信息,这时整个程序运行过程中只需一个实例对象即可,可减少占用内存资源,同时还可以保证程序在多处地方获取的配置信息一致。
2、使用单例模式可进行同步控制,计数器同步、程序多处读取配置信息这些情景下若只存在一个实例,即可保证一致性。
在命令行种使用uvicorn启动web服务,uvicorn main:app --relod
打开本地的http://127.0.0.1:8000/docs#/就能看到fastapi自带的SwaggerUI交互接口文档。
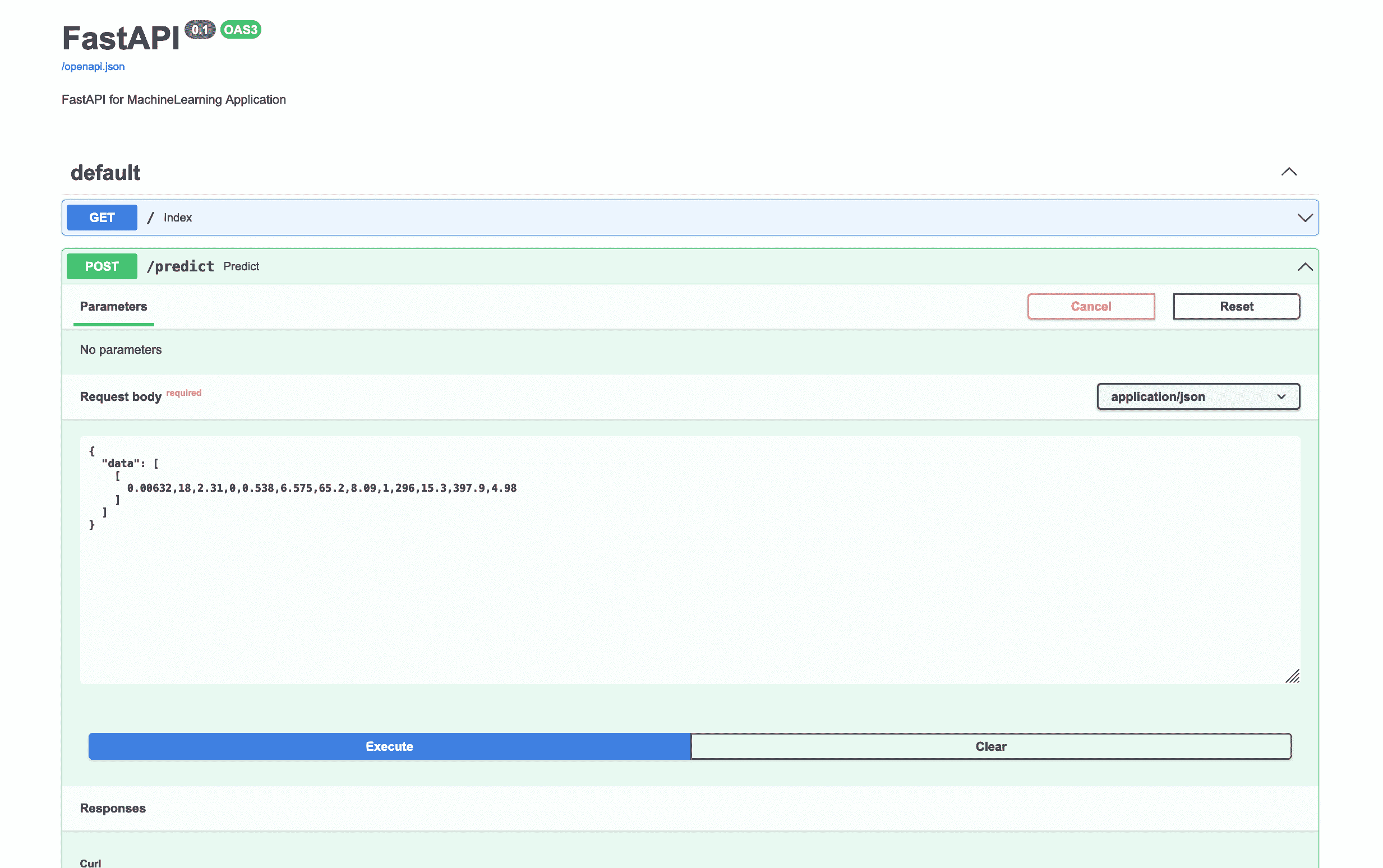
我们在文档中向服务器发送一个请求,试一下部署的应用能否给出正确预测值。
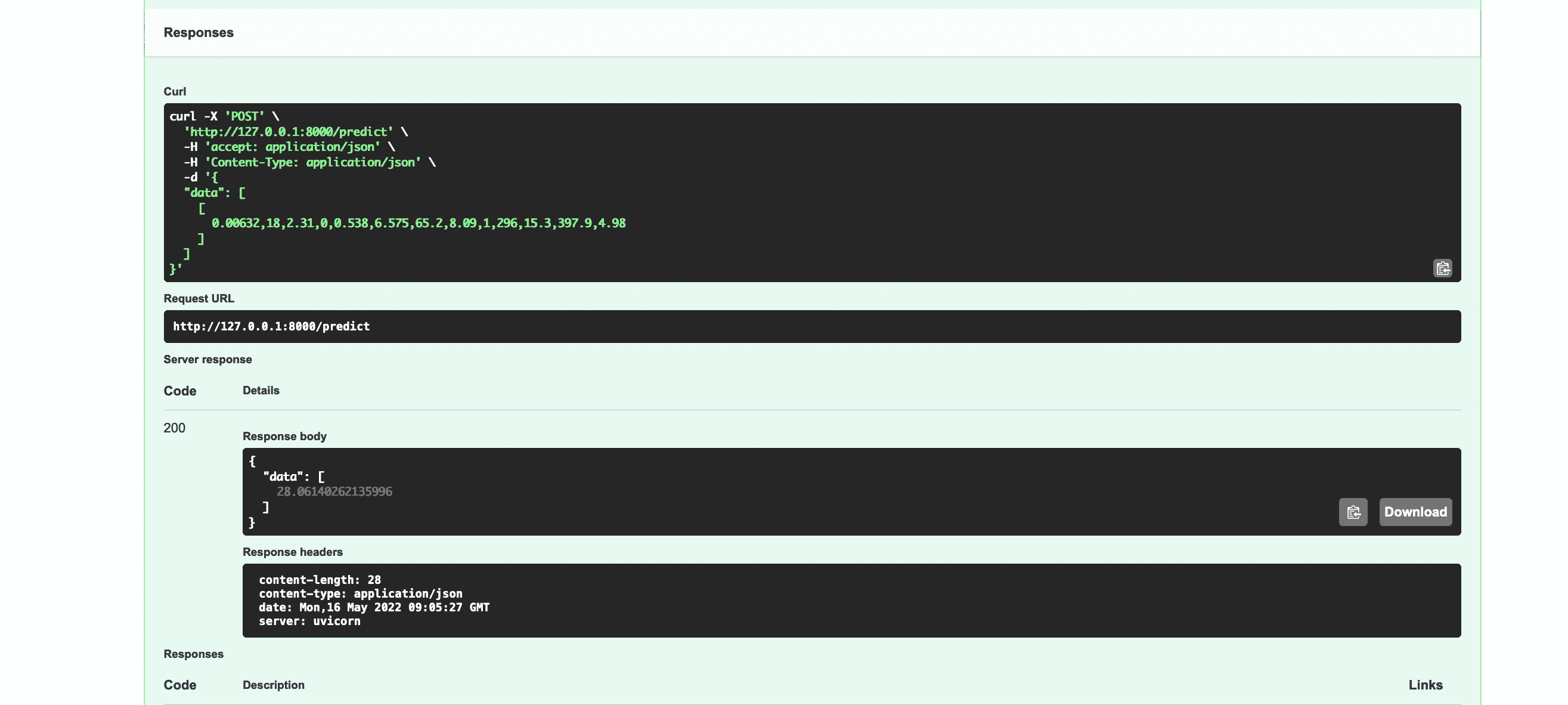
点击Execute就能看到服务器给出了正确的响应。
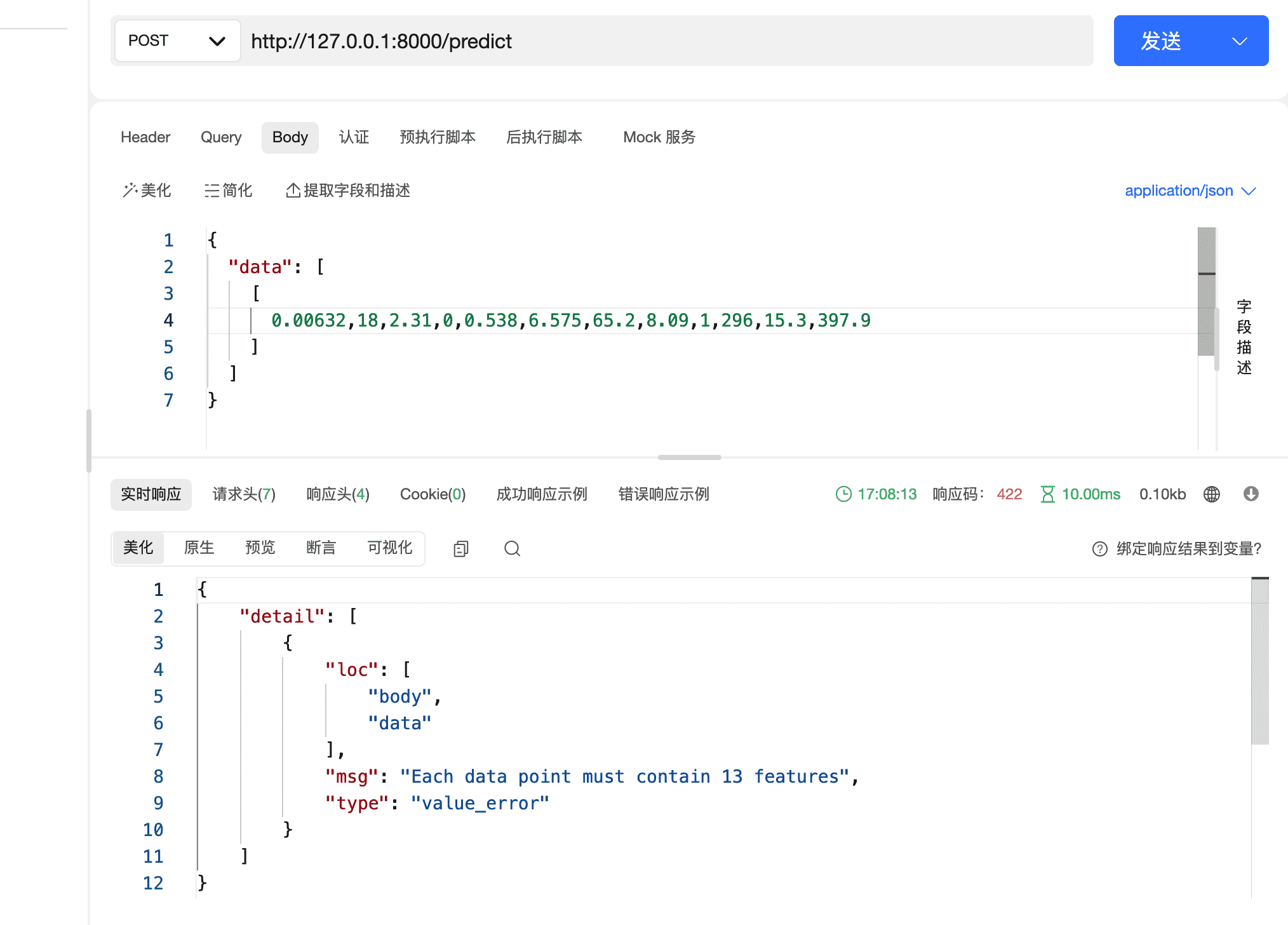
FastAPI另外一个值得学习的地方就是它进行了严格的数据校验,如果用户输入数据不符合我们的定义,也会给出非常好的提示和报错,这大大提高了开发人员和用户的体验。这个应用需要输入原始数据对应的13个特征,比如我们这里只输入12个,他会提示:
3.3 Docker部署
3.3.1 使用 pipreqs 生成requirements.txt
我们还可以通过第三方库 pipreqs 来生成 requirements.txt 文件,这个方式有一个好处,那就是它可以只生成我们当前Python项目中所用到的依赖包及其版本号,而不是像 pip freeze 方式一样把所有包全部列出生成。
# conda install pipreqs
pipreqs . --encoding=utf-8 --force
3.3.2 编写DockerFile
# 1、从官方 Python 基础镜像开始
#FROM python:3.8-slim
FROM ubuntu:18.04
LABEL author="angyi"
ENV LANG=C.UTF-8
ENV LC_ALL=C.UTF-8
# 3、先复制 requirements.txt 文件
# 由于这个文件不经常更改,Docker 会检测它并在这一步使用缓存,也为下一步启用缓存
COPY ./requirements.txt ./requirements.txt
RUN apt-get update &&\
apt-get install --no-install-recommends -y \
python3.8 python3-pip python3.8-dev \
&& pip3 install --upgrade setuptools && pip3 install --upgrade pip
# 4、运行 pip 命令安装依赖项
RUN pip3 install -r requirements.txt
# 5、复制 FastAPI 项目代码
COPY . /fastapi
# 2、将当前工作目录设置为 /code
# 文件和应用程序目录的地方
WORKDIR /fastapi
EXPOSE 8000
ENV PYTHONIOENCODING=UTF-8
# 6、运行服务
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
3.3.3 构建镜像和容器
docker build --file Dockerfile --tag fastapi-boston .
docker run -it -d --name fastapi -p 8000:8000 fastapi-ml-quickstart
完整的代码在这里:github