
多线程Thread、多进程Process、多协程Coroutine
CPU密集型任务
cpu密集型任务也叫计算型密集任务,是指I/O在很短的时间内可以完成,而CPU的处理时间很长,cpu占用率会很高。例如加密解密,压缩和解压缩,正则表达式搜索等。
IO密集型任务
是指任务会对硬盘/内存的读取大大增加,cpu的占用率很低。如文件处理程序,网络爬虫程序,读写数据库等。
多线程 多进程 多协程之间的对比

技术选择

全局解释器锁 (GIL)
即使电脑有多核CPU,单个时刻也只能运行1个线程,遇到io之后转换到另一个线程运行。
为什么要有这个GIL,为了解决多线程之间数据完整性和状态同步问题。有了GIL简化了Python对于共享资源的管理。
这里有两句话非常好的解释了这些疑难点:
- Python的线程是有GIL锁的,所以是单核的。
- Python的进程每个都有独立的GIL锁,所以是多核的,但是每个都需要独立的分配内存空间,所以空间占用大
这也是为什么说的python是假的多线程,线程其实只能运行一个,只不过是在不停切换,所以说python多线程是并发的。而多进程才是真正并行的。
并发可以理解为你一个人烧着水的同时,不会等待,而是去切菜。遇到io时切换到另一个任务,导致cpu会一直在执行任务,不会等待,减少时间浪费。、
并行可以理解为直接开辟了另一个厨房,跟你在同步进行,你烧水,他也烧水。真正的并行处理,只需要一道菜的时间就能做出两道菜。
Python的并发编程模块
多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会单线程等待io时间
多进程:multiprocessing,利用多核cpu的能力,真正的并行执行任务
异步io:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行。
Python 创建多线程的方法

通过 threading.Thread方法 创建
先来一个简单案例,写两个函数,实现一边跳舞一边唱歌:
import threading
import time
def dance():
for i in range(5):
print("dancing.....")
time.sleep(0.1)
def sing():
for i in range(5):
print("singing.....")
time.sleep(0.1) # 等待 就会切换进程
if __name__ == "__main__":
t1 = threading.Thread(target=dance,) # 注意函数不用写括号
t2 = threading.Thread(target=sing)
t1.start()
t2.start()
创建了线程,就是这个函数或者这个功能,可以被丢在后台执行了,不用等他了,可以执行别的了。start方法之后才被丢到后台执行。
下面这个例子说明多线程爬虫的好处
import requests
import threading
def craw(url):
r = requests.get(url)
print(url, len(r.text))
def multi_thread(urls):
threads = []
for url in urls:
threads.append(
threading.Thread(target=craw, args=(url,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
def single_thread(urls):
for url in urls:
craw(url)
if __name__ == '__main__':
urls = [
f'https://www.cnblogs.com/#/p{page}'
for page in range(1, 50 + 1)
]
import time
start = time.time()
single_thread(urls)
end = time.time()
print('single thread cost: ', end - start, 'seconds')
print("======================= ")
start = time.time()
multi_thread(urls)
end = time.time()
print('multi thread cost: ', end - start, 'seconds')
单线程大约耗时10秒,多线程1秒
线程的执行没有前后顺序,操作系统说了算。当调用thread的时候,不会创建线程,调用start方法才会创建线程并开始执行。
通过继承Thread类创建线程
import threading
import time
'''
如果代码逻辑复杂,就用类来写
'''
class MyThread(threading.Thread):
'''
要实现多线程类 就必须复写 run 方法,在这里面调用其他函数
'''
def run(self):
for i in range(3):
time.sleep(1)
msg = "i am "+self.name+'@'+str(i)
print(msg)
# 或者调用其他方法
if __name__ == "__main__":
t = MyThread()
t.start() # 多线程启动的时候还是 用start方法
互斥锁 解决资源竞争问题
利用lock来解决线程安全问题,锁的概念可以理解为通行证,只有一个线程能拥有这个证,能对这个变量进行操作,其他线程无法对其进行操作,从而避免线程切换带来的诸多问题。
同时修改一个变量
先来看一个简单的有问题的例子,用两个函数分别对同一个变量进行相加:
import threading
import time
global_num = 0
def test1(tem):
global global_num
for i in range(tem):
global_num += 1
def test2(tem):
global global_num
for i in range(tem):
global_num += 1
if __name__ == "__main__":
t1 = threading.Thread(target=test1, args=(1000000,)) # 注意args 为 元组 要加逗号
t2 = threading.Thread(target=test1, args=(1000000,))
t1.start()
t2.start()
time.sleep(5)
print(global_num) # 输出并不是2000000
其实这个问题的根本是操作没有做完,要不你把你的做完,要不就别做。跟数据库的事务相似。线程如果是一个写,一个读一般情况不会出问题,但是同时修改就出问题了,那怎么解决这个问题呢,就是用锁;这里用到一种锁,互斥锁。我这个线程再用这个变量的时候,就锁上了,别的线程用不了。这个锁只能锁一次。
import threading
import time
global_num = 0
lock = threading.Lock()
def test1(tem):
global global_num
for i in range(tem):
# 上锁 有一个原则,锁起来的代码越少越好,比放在for外面要好
lock.acquire()
global_num += 1
# 释放锁
lock.release()
print(global_num)
def test2(tem):
global global_num
for i in range(tem):
# 上锁
lock.acquire()
global_num += 1
# 释放锁
lock.release()
if __name__ == "__main__":
t1 = threading.Thread(target=test1, args=(1000000,)) # 注意args 为 元组 要加逗号
t2 = threading.Thread(target=test1, args=(1000000,))
t1.start()
t2.start()
time.sleep(5)
print(global_num)
# 但是这样做跟单线程不是一样的了吗,多线程还有什么意义?
下面这个介绍接近实际的例子,比如银行取钱。
银行取钱业务
import time
import threading
class Account(object):
def __init__(self, account):
self.account = account
def draw_money(account, amount):
if account.account >= amount:
time.sleep(1)
account.account -= amount
print(threading.current_thread().name, "取钱成功")
print(threading.current_thread().name, f"剩余金额{account.account}")
else:
print(threading.current_thread().name, "取钱失败")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(target=draw_money, args=(account, 800))
tb = threading.Thread(target=draw_money, args=(account, 800))
ta.start()
tb.start()
输出:
/Users/angyi/miniforge3/envs/flask/bin/python /Users/angyi/Documents/Flask/multiprocess_learn/06_lock_concurrent.py
Thread-1 取钱成功
Thread-1 剩余金额200
Thread-2 取钱成功
Thread-2 剩余金额-600
Process finished with exit code 0
取钱去了两次都成功了,很明显账户余额出问题了,本来就1000块钱,让你取了1600,两次都成功了。
lock 解决线程安全问题
import time
import threading
lock = threading.Lock()
class Account(object):
def __init__(self, account):
self.account = account
def draw_money(account, amount):
with lock: # 上下文lock
if account.account >= amount:
time.sleep(1)
account.account -= amount
print(threading.current_thread().name, "取钱成功")
print(threading.current_thread().name, f"剩余金额{account.account}")
else:
print(threading.current_thread().name, "取钱失败")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(target=draw_money, args=(account, 800))
tb = threading.Thread(target=draw_money, args=(account, 800))
ta.start()
tb.start()
输出:
/Users/angyi/miniforge3/envs/flask/bin/python /Users/angyi/Documents/Flask/multiprocess_learn/06_lock_concurrent.py
Thread-1 取钱成功
Thread-1 剩余金额200
Thread-2 取钱失败
Process finished with exit code 0
这样就保证了线程安全性。
避免死锁
什么情况会产生死锁?
在线程共享多个资源的时候,如果两个线程分别占有一部分资源,并且同时等待对方释放资源,就会造成死锁。
死锁是一种状态。
比如有两个锁,有两个线程,每个线程刚开始都上了各自一个锁,接下来却都想上另一个锁,那就必须等待对方释放资源,这样就造成了死锁。
为了避免出现这种情况,有两种方法
- 添加超时等待
- 程序设计避免-银行家算法
生产者消费者模式爬虫
- 多组件的Pipeline技术
- 生产者消费者架构
- 多线程数据通信的queue.Queue
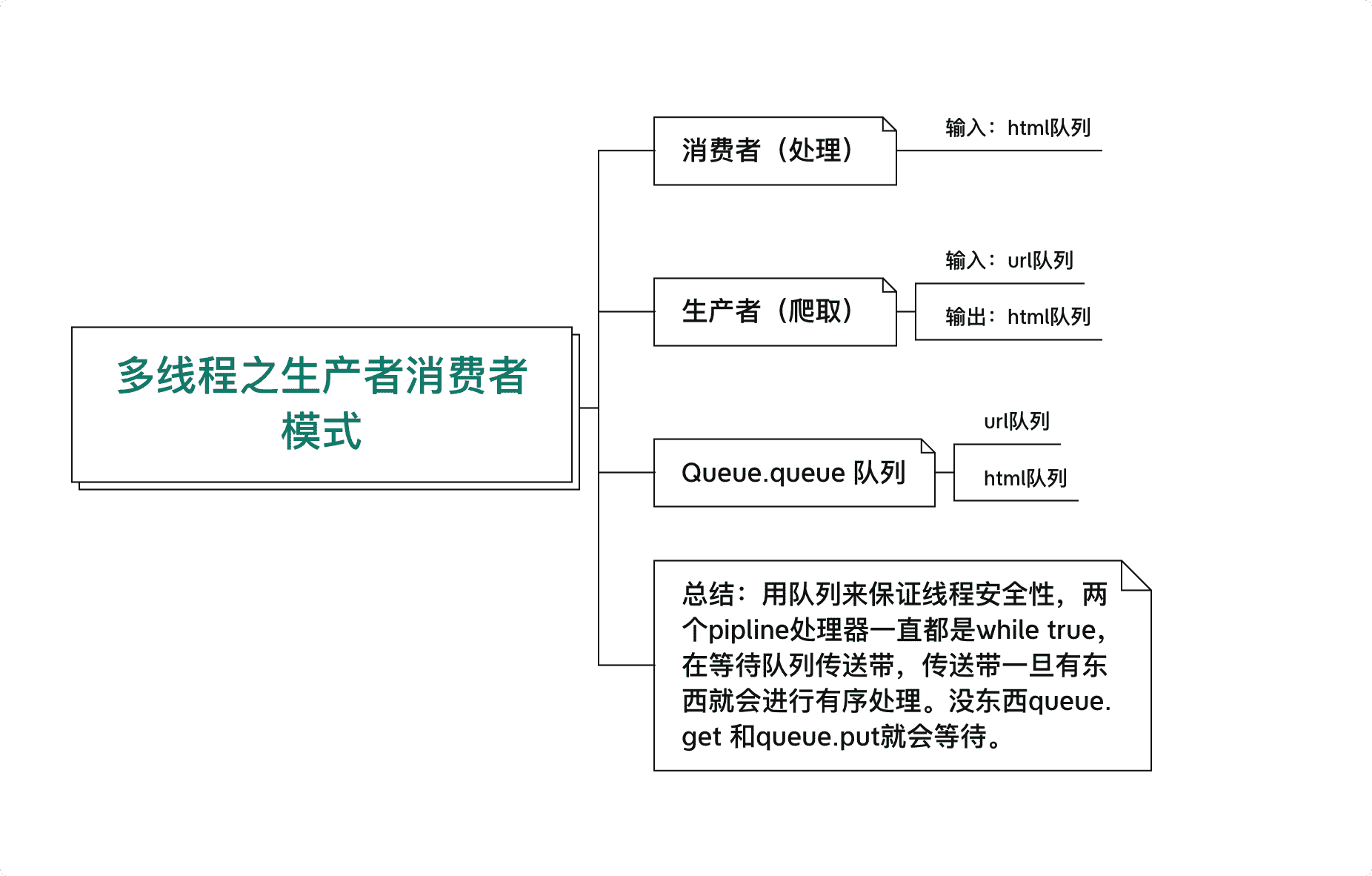
import queue
import random
import time
import threading
import requests
from bs4 import BeautifulSoup
def craw(url):
r = requests.get(url)
return r.text
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a', class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
# 生产者
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = craw(url)
html_queue.put(html)
print("生产者处理", f"当前线程名字{threading.current_thread().name}**当前html队列长度{html_queue.qsize()}")
# 消费者
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = parse(html)
for result in results:
fout.write(str(result) + "\n")
time.sleep(random.randint(1, 2))
print("消费者处理", f"当前线程名字{threading.current_thread().name}---当前队列长度{html_queue.qsize()}")
if __name__ == '__main__':
urls = [
f'https://www.cnblogs.com/#/p{page}'
for page in range(1, 50 + 1)
]
html_queue = queue.Queue()
url_queue = queue.Queue()
for url in urls:
url_queue.put(url)
# 两个生产者线程
for i in range(2):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw {i}")
t.start()
# 三个消费者线程
fout = open('txt.txt', 'w')
for j in range(3):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse {i}")
t.start()